Tail Recursion
fibonacci(피보나치) 수열
잘 알려져 있듯 피보나치 수열은 다음과 같다.
프로그래밍과는 관련 없는 얘기를 살짝 하자면, 이 수열의 이름은 본명은 Leonardo da Pisa이지만 fibonacci로 알려진 12세기 이탈리아 수학자의 이름을 따서 지어졌는데, 사실 이 수열을 가장 먼저 언급한 사람, 즉 가장 먼저 발견한 사람은 피보나치가 아니라 핑갈라라고 하는 기원전 4세기 또는 2세기로 추정되는 시기의 인도인이라고 한다. 위키 참고
암튼 피보나치 수열은 다음과 같이 정의된다.

출처 : 위키피디아
위 식의 가장 아래줄을 보면 n번째 피보나치 수열의 숫자를 구하는 방법을 알 수 있다.
위 식을 그대로 JavaScript로 구현하면 다음과 같다.
참고로 앞으로의 구현 내용에는 n이 음수인 경우에 대한 예외처리는 편의상 생략한다.
피보나치 수의 정의 자체가 재귀 호출 관계를 내포하고 있으므로, 구현 역시 재귀 호출을 포함하게 된다.
콘솔에서 fibonacci(0), fibonacci(1), fibonacci(2), fibonacci(3), … 을 여러 개 실행해보면 맞는 답이 나온다.
그럼 여기서 얘기 끝?
물론 아니다. fibonacci(100)을 실행하면 어떨까?
콘솔이 답을 금방 뱉어내질 않는다. 몇 분을 기다려도 답이 안 나와서 조금 기다리다 이상하다 싶어서 콘솔이나 브라우저 탭을 닫아보면 브라우저가 살짝 맛이 갔다는(실은 속으로 머리터지게 계산 중) 것을 알 수 있다.
전지전능하신 컴퓨터께서 왜 겨우 이 정도에 뻗을까?
겨우 이 정도?
이 글의 주제인 재귀, 반복, Tail Recursion을 빨리 알고 싶다면 이 단원과 다음 단원인 함수 호출의 비용, Stack은 생략하고 바로 해결의 실마리 단원으로 건너 뛰어도 좋다.
100이라는 숫자는 컴퓨터가 다루기에 아주 작은 숫자임에 틀림 없다.
하지만 단순히 100이 아니라 100번째 피보나치 수를 구하는 과정은 얘기가 완전히 다르다.
먼저 100이 아니라 6을 가지고 한 번 재귀 호출 과정을 들여다보자. 참고로 들여쓰기는 다음 단원에서 이야기 할 Stack의 깊이를 나타낸다.
어떤가. 6으로도 충분히 현기증이 난다. 하지만 사람에게나 현기증 나지 컴퓨터는 이 정도는 끄떡 없다?
맞는 얘기다. 이 정도는 끄떡 없다. fibonacci(6) 정도는 끄떡 없지만 fibonacci(100)에서는 컴퓨터가 뻗었다.
이 시점에서 fibonacci(6)을 구하는데 몇 번의 함수 호출이 있었는지 한 번 세어보자.
앞의 현기증 나는 호출 과정을 뒤져보면 6번째 피보나치 수인 8을 구하는데 총 25번의 함수 호출이 동원된다는 것을 알 수 있다. 그럼 fibonacci(100)을 구하는데는 몇 번의 함수 호출이 필요할까? 정확한 값을 알아보기 전에 먼저 n이 0부터 6일때 까지의 fibonacci(6)을 구하는데 필요한 함수 호출 횟수를 세어보자.
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 함수 호출 횟수 | 1 | 1 | 3 | 5 | 9 | 15 | 25 |
위의 표에서 함수 호출 횟수의 패턴이 눈에 보인다면 당신의 IQ는.. 살아가는데 크게 무리 없을 만큼 충분히 훌륭하다. ㅋ
피보나치 수열과 비슷하게 먼저 앞의 두 수를 더하고, 그 다음에 추가로 1을 더한 값이 바로 함수 호출 횟수의 패턴이다. 사실 이 패턴은 굳이 위와 같이 계산하지 않고도 f(n) == return f(n - 1) + f(n - 2)라는 등식을 떠올릴 수 있다면 파악할 수 있다. 이렇게 파악할 수 있다면 당신의 IQ는.. 살아가는데 크게 무리 없을 만큼 충분히 훌륭하다!!
암튼 이 패턴을 토대로 내친 김에 n = 14 까지의 값을 구해서 피보나치 수와 비교해보면 다음과 같다.
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 함수 호출 횟수 | 1 | 1 | 3 | 5 | 9 | 15 | 25 | 41 | 67 | 109 | 177 | 287 | 365 | 653 | 1019 |
| 피보나치수 | 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | 144 | 233 | 377 |
단순 재귀 호출 방식으로 n번째 피보나치 수를 구하는데 필요한 함수 호출 횟수는 얼추 봐도 n번째 피보나치 수 보다 2배 이상 크다. 따라서 100번째 피보나치 수를 구하는데 필요한 함수 호출 횟수는 100번째 피보나치 수보다 2배 이상 클 것이다. 100번째 피보나치 수는 여기에서 구할 수 있다. 무려 21자리의 수인 354,224,848,179,261,915,075 이다. 3해 5,422경 4,848조 1,792억.. 어휴 읽기도 힘들다.. 암튼 어마어마 한 수다. 함수 호출 횟수는 이 수의 두 배 이상이니 7해 #,###경 #,###조 #,###억..가 되겠다.
결국 ‘겨우 이 정도’가 아니고 컴퓨터도 충분히 뻗을만한 규모다.
함수 호출의 비용, Stack
피보나치의 수를 예로 들다보니 함수 호출 횟수라는 문제가 대두되었는데, 재귀 호출을 이용하는 조금 더 단순한 문제인 n까지의 합을 구하는 경우를 생각해보면 다른 문제가 나타난다.
이번에도 n을 마음껏 키워보자.
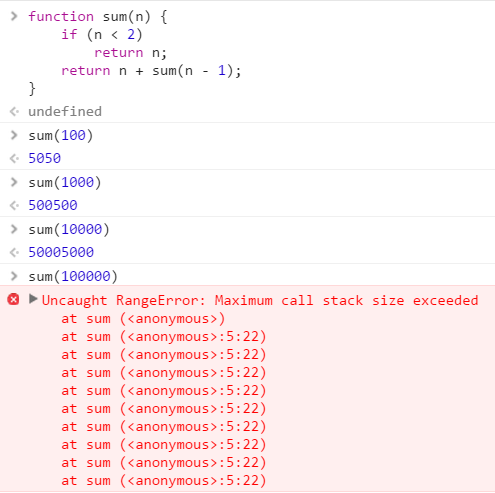
이번에는 Stack 문제다.
함수를 호출한 후에 원래 자리로 돌아오려면, 원래 자리를 어딘가에 저장해둬야 하는데, 그 어딘가가 바로 Stack이다. 함수를 한 번 호출하면 Stack 깊이를 하나 증가시켜서 돌아올 원래 자리에 대한 정보를 저장하고, 호출된 함수가 일을 마치고 리턴되면 Stack에서 원래 자리에 대한 정보를 빼와서 원래 자리로 돌아가므로, Stack 깊이가 하나 줄어 원래 깊이로 되돌아 간다.
호출된 함수가 리턴되기 전에 또 함수를 호출하는 것이 반복되면 Stack 깊이는 계속 증가하게 된다. 위와 같이 구현된 sum(100000)을 실행하면 함수가 리턴되기 전에 계속 sum 함수를 호출하므로 Stack 깊이가 10만까지 계속 증가하게 된다. 어느 한도를 넘으면 결국 위와 같은 에러가 발생한다. 참고로 브라우저 Stack 깊이의 한계는 맨 아래의 더 읽을거리에서 확인해 볼 수 있다.
암튼 Stack 쪽의 문제는 Stack 깊이의 증가에 있다.
다시 피보나치의 수로 돌아와서.. 그렇다면 이 성능 좋은 컴퓨터를 가지고 겨우 100번째 피보나치 수열도 못 구한단 말인가?
해결의 실마리
그럴리가.. 문제를 다시 정리해보자.
- 재귀 호출로 구하려니 함수 호출 횟수가 너무 커서 문제다.
- Stack 깊이가 너무 깊어져도 문제다.
먼저 함수 호출 횟수부터 생각해보자. n까지의 합을 구할 때는 함수 호출 횟수 문제 이전에 Stack 문제가 발생했다. 즉, n까지의 합을 구할 때는 함수 호출 횟수가 그리 많지 않았다. 하지만 피보나치의 수를 구할 때는 함수 호출 횟수가 피보나치의 수 이상으로 커져버렸다. 이유가 뭘까?
n까지의 합을 구할 때는 재귀 호출을 한 겹으로 사용했는데, 피보나치의 수를 구할 때는 바로 앞의 피보나치의 수와 앞의 앞의 피보나치의 수 이렇게 두 겹으로 재귀 호출을 사용했기 때문이다. 따라서 다음과 같은 실마리를 얻을 수 있다.
- 재귀 호출을 한 겹으로 할 수 있다면 함수 호출 횟수를 획기적으로 줄일 수 있다.
그렇다면 두 번째 문제인 Stack 깊이가 증가하지 않게 하려면 어떻게 해야할까?
크게 두 가지 방법이 있을 것 같다.
- 아예 Stack을 쓰지 말아버리자. 즉, 함수를 호출하지 말자.
- Stack을 쓰되 새로 추가해서 누적시키지 말고 있는 걸 재사용하자.
먼저 함수를 호출하지 않는 방법을 생각해보자.
반복
fibonacci(100)은 결국 자기 자신을 여러번 반복해서 호출하게 된다. 그렇다. 피보나치 정의에 따라 구현하다보니 그냥 재귀 호출을 떠올려버렸지만, 피보나치 수를 구하는 과정은 본질적으로 반복이다.
함수 호출을 하지 말고 알맞은 로직을 반복하면 함수 호출에 의한 Stack 사용은 피할 수 있는 것이다.
그러려면 반복할 때마다 나온 계산 결과를 어딘가에 저장해두고 그 다음 반복에서는 앞 단계에서 저장한 값에 새로운 값을 반영하는 방식으로 구현해야 한다.
이 정도의 힌트를 가지고 반복을 이용해서 피보나치의 수 구하기를 직접 구현해보자.
피보나치 수열 구하기는 n까지의 합이나 n의 계승(factorial)을 구하는 것보다는, 알고보면 다를 거 없지만 모르고 보면 살짝 까다로운 면이 있다. 재귀를 반복으로 변환하는데 반드시 필요한 생각 거리가 담겨 있으므로 꼭 직접 해 볼 것을 권장한다.
재귀 호출 대신 반복을 사용한 방식은 다음과 같다.
이제 finonacciLoop(100)을 실행해보면 브라우저가 죽지 않고 금방 답을 보여준다.
잠시 샛길로 새보자면, 콘솔이 보여주는 답에는 사실 오차가 있다.
9999999999999999(16자리) === 10000000000000000(17자리) 가 true를 반환하며,
10000000000000000(17자리) === 10000000000000001(17자리) 도 true로 나오고,
9999999999999999(16자리) === 10000000000000001(17자리) 도 true로 나온다.
이유는 JavaScript의 숫자는 언제나 64-bit 배정도 부동소수형으로 정확도의 한계가 있기 때문이다.
참고 w3schools
위의 과정을 풀어보면 다음과 같다.
반복 횟수도 n번 이하이고, 반복을 계속해도 함수 호출에 의한 Stack이 추가되는 일은 없다.
생각을 바꾸니 의외로 간단하게 해결되었다. 재귀 호출을 반복으로 바꾸는 과정에서 꼭 머리에 새기고 넘어가야할 것은 다음과 같다.
반복 단계별 계산 결과를 반복이 끝날 때까지 어떤 변수(여기서는 previousFibo)에 계속 저장한다.
Tail Call
앞에서 함수 실행 후 돌아갈 원래 자리를 Stack에 저장한다고 했는데, 원래 자리로 돌아가야만 하는 이유가 뭘까?
원래 자리로 돌아가야만 하는 이유는 원래 자리에서 해야할 일이 남아있기 때문이다.
앞에서 다룬 가장 직관적인 fibonacci 함수를 다시 보자.
4라인 return fibonacci(n - 1) + fibonacci(n - 2);을 보면 fibonacci(n - 1)를 호출한 후에 바로 리턴하는 것이 아니라 다시 한 번 fibonacci(n - 2)를 실행해서 두 값을 더한 후에 리턴한다. 다시 말해, 원래 자리로 돌아와서 해야할 일이 남아있으므로 돌아올 원래 자리의 정보를 Stack에 추가해서 저장해야 한다.
바꿔 말하면, 원래 자리에서 해야할 일이 남아있지 않다면 돌아갈 원래 자리를 Stack에 추가로 저장할 필요가 없다.
그렇다면 원래 자리에서 해야할 일을 남겨두지 않는 방법은 무엇인가?
그 방법이 바로 Tail Call이다.
Tail Call은 직역해서 보통 꼬리 호출 이라고 하는데, 마무리 호출이나 끝물 호출이라고 이름 붙였다면 직관적으로 더 쉽게 이해할 수 있지 않았을까.. 암튼 Tail Call이 뭔지 짧게 알아보자.
3라인을 보면 b 함수를 호출하는데, b(v) 실행 값을 반환 받은 후 아~~무일도 하지 않고 바로 반환해버린다. 이러면 굳이 돌아올 곳을 저장할 필요 없이 그냥 반환 받은 값을 다시 반환해버리면 되지 않을까?
맞는 얘기다. 그리고 어떤 함수를 호출하고 반환 받은 후 아무 일도 하지 않고 바로 반환하려면 그 함수를 논리적으로 가장 마지막에 호출해야 한다. 물리적인 위치가 기준이 아니라 논리적인 위치가 기준이다.
위의 코드를 살짝 바꾼 아래의 코드는 Tail Call일까 아닐까?
3라인을 보면 b의 호출이 물리적으로 가장 마지막에 위치하기는 하지만, Tail Call 이 아니다. 3라인을 return b(--v);로 바꾸면 Tail Call에 해당한다.
이제 Tail Call을 다음과 같이 정의할 수 있겠다.
Tail Call은 함수를 호출해서 값을 반환 받은 후 아무 일도 하지 않고 바로 반환하게 하기 위해 논리적으로 가장 마지막(꼬리) 위치에서 함수를 호출하는 방식을 말한다.
따라서 Tail Call 방식을 적용하려면 두 겹인 재귀 호출을 한 겹으로 줄여야만 한다.
Tail Call Optimization
그런데, 프로그래머가 할 수 있는 일은 여기까지다. 즉, 반환 받은 후 아무일도 하지 않게끔 하는 Tail Call 방식으로 짜는 것까지는 프로그래머가 할 수 있는 일이지만, Tail Call 방식으로 짰다고 해도 그런 코드를 돌리는 실행 환경에서는 내부적으로 여전히 Stack을 새로 만들어 추가하는 비효율적인 방식으로 동작할 수도 있다.
이름에서도 짐작할 수 있는 Tail Call 최적화는 다음과 같다.
Tail Call 방식으로 짜여지면 Stack을 새로 만들지 않고 이미 있는 Stack 속의 값만 대체해서 Stack을 재사용하는 방식으로 동작하도록 최적화 할 수 있다. 이러한 최적화를 Tail Call Optimization(또는 Tail Call Elimination)이라고 하며 언어의 실행 환경에서 지원해줘야 한다.
Tail Recursion
그럼 Tail Recursion은 또 뭔가. 짐작 하겠지만 다음과 같다.
Tail Call의 특별한 경우로서 Tail Call로 호출하는 함수가 자기 자신인 경우
이제 Tail Recursion으로 fibonacci 수를 구하는 코드를 짜보자. 앞에서 재귀 호출 방식을 반복 방식으로 바꾸는 작업을 직접 해봤다면 크게 어렵지 않을 것이다.
fibonacciTailRecursion(100, 1, 0)을 실행해보면 반복 방식과 마찬가지로 브라우저가 죽지 않고 금방 답을 보여준다. 오오~ 드디어 재귀 호출을 쓰는 방식으로도 100번째 피보나치 수를 계산해냈다(물론 오차가 묻어있지만).
어떻게 이게 가능해졌을까?
Tail Recursion을 적용하기 위해 두 겹이었던 재귀 호출을 한 겹으로 바꿔서 함수 호출 횟수가 확 줄었기 때문이다. 얼마나 줄었을까? 7해 #,###경 #,###조 #,###억..회에서 100회로 완전히 획기적으로 줄어들었다.
재귀 호출을 두 겹에서 한 겹으로 줄인 효과는 실로 막대하다.
4~6라인에서 볼 수 있듯이 previousFibo에 계산값을 계속 저장하는 로직은 반복 방식의 for 문 안에 있던 것과 완전히 동일하다.
그리고 7라인에서 볼 수 있듯이 두 겹이었던 재귀 호출을 한 겹으로 바꿨다.
반복 방식에서는 previousFibo이 반복문 외부에서 선언되었고, Tail Recursion 방식에서는 previousFibo이 함수의 파라미터로 사용된다는 점만 다를 뿐, 반복이나 꼬리 호출 단계별 계산 결과를 어딘가에 저장해둔다는 점은 똑같다.
참고로 반복 방식과 동일한 로직이 사용될 수 있다는 면을 보여주기 위해 위와 같이 구현했지만, 사실 조금 더 깔끔한 답안은 아래와 같다.
결국 f(n) = f(n - 1) + f(n - 2)를 f(n, fibo1, fibo2) = f(n - 1, fibo1 + fibo2, fibo1)로 바꿔서 두 겹이었던 재귀 호출을 한 겹으로 바꾼 것이다.
위에서 구현한 Tail Recursion 호출 과정을 n = 6 일때를 예를 들어 풀어보면 아래와 같다. 들여쓰기는 Stack의 깊이를 나타낸다.
위에서 보았던 것보다 훨씬 깔끔하다. 함수 호출 횟수도 25회에서 n과 동일한 6회로 줄었다.
여기에 Tail Call Optimization이 적용되면 다음과 같이 Stack의 사용마저 최적화 된다.
그런데, JavaScript는 Tail Call Optimization을 지원 해주고 있을까?
JavaScript의 Tail Call Optimization
ECMAScript 6에서는 공식적으로 Tail Call Optimization을 지원한다. 하지만 https://kangax.github.io/compat-table/es6/ 에 따르면 2015년 7월 28일 현재 실제로 Tail Call Optimization을 지원하고 있는 브라우저는 없다.

출처 : https://kangax.github.io/compat-table/es6/
실제로 그런지 한 번 확인해보자.
피보나치의 수는 Tail Call Optimization을 확인하기에는 적당하지 않다. 이유는 Stack을 깊이 가져가기 위해 n의 값을 크게 가져가면, 피보나치의 수가 너무 커져서 계산을 제대로 못해내기 떄문이다. n이 겨우 100일 때 피보나치의 수는 3해 5,422경 4,848조 1,792억이 넘는 큰 수 였다는 것을 다시 떠올려보면 이해가 갈 것이다.
따라서 n까지의 합을 통해 브라우저의 Tail Call Optimization 지원 여부를 확인해보자.
단순 재귀 호출 버전
앞의 함수 호출의 비용, Stack 단원에서 살펴봤던 것처럼, 단순 재귀 호출 방식에서는 Chrome 기준으로 n = 10만이면 에러가 났었다.
따라서 Tail Recursion 방식으로 n = 10만일때 값을 계산할 때 Stack 에러가 나지 않고 제대로 계산한다면 Tail Call Optimization이 적용되어 있다고 근사적으로 판단할 수 있다.
Tail Recursion 버전
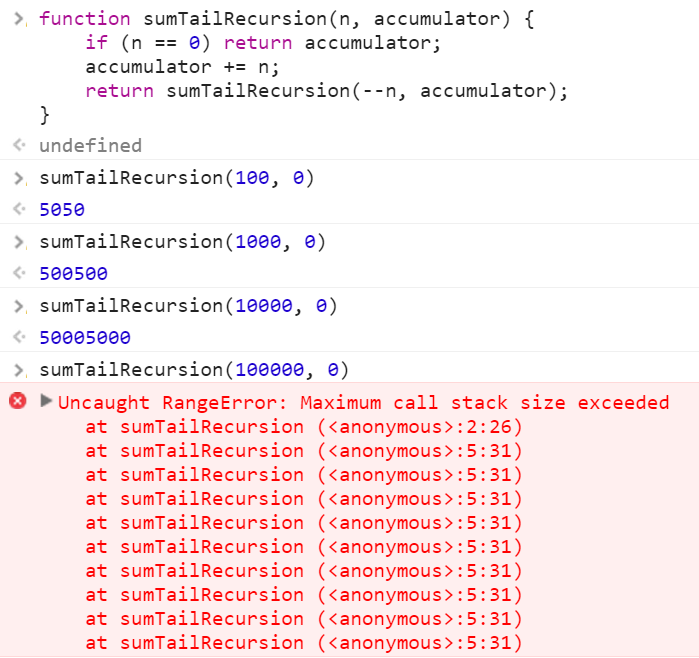
Chrome에서는 보는 바와 같이 n = 1만까지는 괜찮지만 n = 10만을 실행하면 단순 재귀 호출 방식일 때와 마찬가지로 Stack 에러가 발생한다. 참고로 Mozilla에서는 n = 1만에서도 에러가 발생한다.
즉, JavaScript의 실행 환경 중의 하나인 브라우저에서는 2015년 7월 28일 현재, Tail Call Optimization을 지원하지 않고 있다.
따라서, Stack 에러를 피하려면 반복을 사용하는 것이 좋겠다.
반복 버전
반복 버전은 다음과 같다.
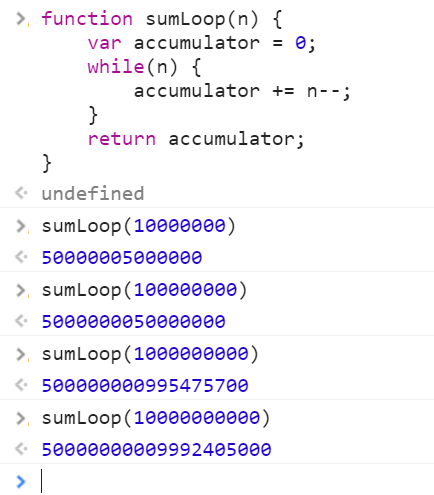
반복 버전의 경우 n = 1억 까지는 거의 바로 계산 결과가 나오고, n = 10억에서도 2초가 채 안 걸린 듯 하고, n = 100억은 10초 이상 소요가 되지만 계산 결과가 나오기는 한다. 물론 앞에서 언급한 JavaScript의 부동소수형 정확도 한계로 인한 오차는 있다.
정리
재귀 호출은 무한루프를 타지 않도록 탈출 로직만 잘 다듬으면 전체적으로는 직관적이고 이해하기 쉬운 코드를 작성할 수 있게 해준다.
하지만 재귀 호출을 두 겹 이상으로 사용하면 함수 호출 횟수가 상상하지 못할 정도로 증가하는 문제가 발생하고, 재귀 호출 깊이가 깊어지면 Stack을 많이 사용하는 문제가 발생한다.
이럴 때는 재귀 호출 대신 반복이나 Tail Recursion 방식으로 구현하면 문제 상황을 피해갈 수 있다.
만약 JavaScript처럼 실행 환경에서 Tail Call Optimization을 지원해주지 않으면 사실 상 유일한 해결책은 반복문 뿐이다.
재귀 호출을 반복이나 Tail Recursion 방식으로 구현하려면 다음의 사항을 꼭 기억하자.
반복이나 꼬리 호출 단계별 계산 결과를 어딘가에 계속 저장한다.
더 읽을거리
- 위키피디아 Tail Call - https://en.wikipedia.org/wiki/Tail_call
- Java의 Tail Call - http://www.drdobbs.com/jvm/tail-call-optimization-and-java/240167044
- JavaScript의 Tail Call - http://www.2ality.com/2015/06/tail-call-optimization.html
- 브라우저의 재귀 호출 깊이 한계 - http://jsfiddle.net/9YMDF/9/
- 류종택의 프로그래밍 강의실 - http://ryulib.tistory.com/318

댓글
댓글 쓰기